持久化,迁移和升级¶
数据序列化¶
在 OpenERP 安装的时候, 创建和填充数据库是必须的两个步骤:
- 创建 SQL 表
- 插入不同的数据到表中
由于服务器中的对象描述,SQL表的创建和修改时自动的.
使用 OpenERP, 除了对象的业务逻辑以外,其它都存在数据库中. 例如(不存入数据库):
- reports的定义,
- fields的默认值,
- 每个文档(views)的用户接口的定义 ,
- 菜单,按钮和动作的关系
- 等等其他.
必须有一个机制去描述, 修改和装载这些不同的数据. OpenERP 的数据可以以模块提供的 CSV, XML or YAML 的序列化文件的形式指定模块 modules, 并在模块安装和升级时装载以便填充和升级数据库表.
XML 数据序列化¶
4.2版本之后, OpenERP 提供基于XML的数据序列化格式.
基本的 OpenERP XML 文件格式如下:
<?xml version="1.0"?>
<openerp>
<data>
<record model="model.name_1" id="id_name_1">
<field name="field1">
field1 content
</field>
<field name="field2">
field2 content
</field>
(...)
</record>
<record model="model.name_2" id="id_name_2">
(...)
</record>
(...)
</data>
</openerp>
Fields 内容是 strings 类型,保存在以 UTF-8 编码的 XML 格式的文件中.
下面是一个来自 OpenERP 的源码的例子 (base_demo.xml 在 base 模块中):
<record model="res.company" id="main_company">
<field name="name">OpenERP SA</field>
<field name="partner_id" ref="main_partner"/>
<field name="currency_id" ref="EUR"/>
</record>
<record model="res.users" id="user_admin">
<field name="login">admin</field>
<field name="password">admin</field>
<field name="name">Administrator</field>
<field name="signature">Administrator</field>
<field name="action_id" ref="action_menu_admin"/>
<field name="menu_id" ref="action_menu_admin"/>
<field name="address_id" ref="main_address"/>
<field name="groups_id" eval="[(6,0,[group_admin])]"/>
<field name="company_id" ref="main_company"/>
</record>
最后的字段定义的 admin user :
- 登录,密码等字段比较直接.
- ref 属性用于填充两个记录之间的关系 :
<field name="company_id" ref="main_company"/>
company_id 字段是一个多对一(many2one) 从USER对象到 COMPANY 对象, main_company 是关系的 id.
- eval 属性允许将一些 python 代码放进 xml 中: 这里 groups_id 字段是一个多对多(many2many)的关系. 对于这样一个字段, “[(6,0,[group_admin])]” 的意思为 : 删除所有与当前用户相关的组,并使用 [group_admin] 作为新的关联组 (and group_admin 是另一个记录的 id ).
- search 属性允许你在不指定 xml id 的情况下. 查找相关的记录. 你可以指定一个搜索条目来寻找想要查询的字段. 条目是一个 tuple 的 lists 用于预定义的搜索方法, 如果有多个结果, 通常选中(第一个):
<field name=”partner_id” search=”[]” model=”res.partner”/>
只是 search 在演示数据的一个经典的例子:这里我们并不关心用哪一个 partner 来进行测试,所以我们给出一个空的 list . 注意 model 属性是必须的.
一些典型的 XML 元素描述如下.
记录标签¶
通过 record 标签来实现新数据的添加. 这里 : model 属性是必须的. Model 是插入数据的对象名. 它还有一个可选的属性: id. 如果给出该属性, 在同一个文件中, 这个名字对应的变量将在以后使用, 以便生成新产生资源 ID 的引用.
一个 record 标签可以包含多个 field 标签. 他们指定了记录的 fields 值. 如果不指定一个 field 默认值将会被使用.
例子¶
<record model="ir.actions.report.xml" id="l0">
<field name="model">account.invoice</field>
<field name="name">Invoices List</field>
<field name="report_name">account.invoice.list</field>
<field name="report_xsl">account/report/invoice.xsl</field>
<field name="report_xml">account/report/invoice.xml</field>
</record>
YAML 数据序列化¶
YAML 是 human-readable 可读的数据序列化格式 概念源于 C, Perl, Python, 主意来自 XML 和电子邮件的数据格式. YAML stands for YAML Ain’t Markup Language (yes, that’s a recursive acronym). YAML 用于 OpenERP 数据格式 as of OpenERP 6.0, 有以下优点:
- 作为当前的 XML 格式的一个用户友善的备选格式.
- 在相同的系统模块中进行数据的装载,测试集成.
- 内建与 OpenERP 以便开发复杂的 Python 测试.
- 方便非开发人员写功能测试.
下面是一个 XML 记录和 YAML 记录的比较.
首先,XML 记录使用当前的 XML 序列化格式: (参阅 previous section )
<!--
Resource: sale.order
-->
<record id="order" model="sale.order">
<field name="shop_id" ref="shop"/>
<field model="product.pricelist" name="pricelist_id" search="[]"/>
<field name="user_id" ref="base.user_root"/>
<field model="res.partner" name="partner_id" search="[]"/>
<field model="res.partner.address" name="partner_invoice_id search="[]"/>
<field model="res.partner.address" name="partner_shipping_id" search="[]"/>
<field model="res.partner.address" name="partner_order_id" search="[]"/>
</record>
<!--
Resource: sale.order.line
-->
<record id="line" model="sale.order.line">
<field name="order_id" ref="order"/>
<field name="name">New server config + material</field>
<field name="price_unit">123</field>
</record>
<record id="line1" model="sale.order.line">
<field name="order_id" ref="order"/>
<field name="name">[PC1] Basic PC</field>
<field name="price_unit">450</field>
</record>
YAML 记录¶
#<!--
# Resource: sale.order
# -->
-
!record {model: sale.order, id: sale_order_so4}:
amount_total: 3263.0
amount_untaxed: 3263.0
create_date: '2010-04-06 10:45:14'
date_order: '2010-04-06'
invoice_quantity: order
name: SO001
order_line:
- company_id: base.main_company
name: New server config + material
order_id: sale_order_so4
price_unit: 123.0
- company_id: base.main_company
name: '[PC1] Basic PC'
order_id: sale_order_so4
price_unit: 450.0
order_policy: manual
partner_id: base.res_partner_agrolait
partner_invoice_id: base.main_address
partner_order_id: base.main_address
partner_shipping_id: base.main_address
picking_policy: direct
pricelist_id: product.list0
shop_id: sale.shop
YAML Tags¶
data¶
- Tag: data
必选属性: None
可选属性: noupdate : 0 | 1
子节点:
- menuitem
- record
- workflow
- delete
- act_window
- assert
- report
- function
- ir_set
样例:
- !context noupdate: 0
record¶
- 标签: record
- 必选属性:
- model
可选属性: noupdate : 0 | 1
- 子节点标签:
- field
- 可选属性:
- id
- forcreate
- context
样例:
- !record {model: sale.order, id: order}: name: "[PC1] Basic PC" amount_total: 3263.0 type_ids: - project_tt_specification - project_tt_development - project_tt_testing order_line: - name: New server config order_id: sale_order_so4 - name: '[PC1] Basic PC' order_id: sale_order_so4
field¶
标签: field
- 必选属性:
- name
- 可选属性:
- type
- ref
- eval
- domain
- search
- model
- use
- 子节点标签:
- text node
样例:
-price_unit: 450 -product_id: product.product_product_pc1
workflow¶
- 标签: workflow
- 必填属性:
- model
- action
- 可选属性:
- uid
- ref
- 子节点标签:
- value
样例:
- !workflow {action: invoice_open, model: account.invoice}: - eval: "obj(ref('test_order_1')).invoice_ids[0].id" model: sale.order - model: account.account search: [('type', '=', 'cash')]
function¶
- 标签: function
- 必选属性:
- model
- name
- 可选属性:
- id
- eval
- 子节点标签:
- value
- function
样例:
- !function {model: account.invoice, name: pay_and_reconcile}: -eval: "[obj(ref('test_order_1')).id]" model: sale.order
value¶
- 标签: value
必选属性: None
- 可选属性:
- model
- search
- eval
子节点属性: None
样例:
-eval: "[obj(ref('test_order_1')).id]" model: sale.order
act_window¶
- 标签: act_window
- 必选属性:
- id
- name
- res_model
可选属性:
- domain
- src_model
- context
- view
- view_id
- view_type
- view_mode
- multi
- target
- key2
- groups
子节点标签: None
样例:
- !act_window {target: new, res_model: wizard.ir.model.menu.create, id:act_menu_create, name: Create Menu}
report¶
- 标签: report
- 必选属性:
- string
- model
- name
可选属性:
- id
- report
- multi
- menu
- keyword
- rml
- sxw
- xml
- xsl
- auto
- header
- attachment
- attachment_use
- groups
子节点标签: None
样例:
- !report {string: Technical guide, auto: False, model: ir.module.module, id: ir_module_reference_print, rml: base/module/report/ir_module_reference.rml, name: ir.module.reference}
ir_set¶
- 标签: ir_set
必选属性: None
可选属性: None
- 子节点属性:
- field
样例:
- !ir_set: args: "[]" name: account.seller.costs value: tax_seller
delete¶
- 标签: delete
- 必选属性:
- model
- 可选属性:
- id
- search
子节点标签: None
样例:
- !delete {model: ir.actions, search: "[(model,like,auction.)]"}
assert¶
- 标签: assert
- 必选属性:
- model
- 可选属性:
- id
- search
- string
- 子节点标签:
- test
样例:
- !assert {model: sale.order, id: test_order, string: order in progress}: - state == "progress"
写一个 YAML 测试¶
Note
参考第三部分 3 YAML 自动测试指南 自动化YAML测试指南
- 手工写
- 记录的 CRUD
- 工作流过渡
- 段言 (像在 XML 中的语句)
- 纯 Python 代码
使用 base_module_record(er)
- 生成带有 record 和 workflow 的 YAML 文件
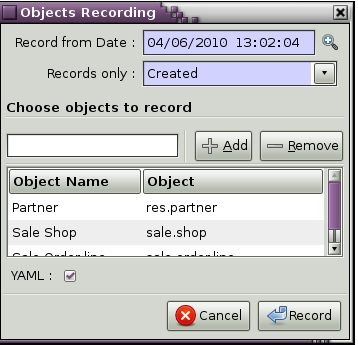
- 用 assertions / Python 代码更新这个 YAML
Warning
重要
yaml 的结构采用(像 Python)缩进, 每一个 child 标签(sub-tag) 相对于父标签进行缩进.
Field Tag¶
- text
- 用双引号在前面或后面包含输入的文字.
- Ex: name: “[PC1] Basic PC”
- integer and float
- Ex: price_unit: 450 Ex: amount_total: 3263.0
- boolean
- active: 1
- datetime
- date_start: str(time.localtime()[0] - 1) + -08-07
- selection
- 给出一个缩写
- Ex: title: M.
- many2one
- 如果它是 res_id 的引用, 指向 res_id
- Ex: user_id: base.user_root
- 如果它的值是基于搜索条目,那么指定 model 到搜索条目
- Ex: object_id: !ref {model: ir.model, search: “[(‘model’,’=’,’crm.claim’)]”}
- one2many
- start each record in one2many field on a new line with a space and a hyphen
- Ex: order_line: name: New server config order_id: sale_order_so4 ......
name: ‘[PC1] Basic PC’ order_id: sale_order_so4 ......
- many2many
- 用每一个 many2many 字段,以空格和连字符开始
- Ex: type_ids: - project_tt_specification ** **- project_tt_development - project_tt_testing
Value tag¶
- 如果Tag能被评估(like res_id is available), 像下面一样写 value tag :
- - !function {model: account.invoice, name: pay_and_reconcile}: - eval: “obj(ref(‘test_order_1’)).amount_total” model: sale.order
这会捕获一个 ‘sale.order’ 记录的 ‘amount_total’ 值伴随 res_id ‘test_order_1’
- 如果值是在一些基于条目的模块上被搜索, 那么就像下面一样写 value tag :
- - !function {model: account.invoice, name: pay_and_reconcile}: - model: account.account search: “[(‘type’, ‘=’, ‘cash’)]” 这将抓取所有 account.account 记录类型等于 ‘cash’
Test Tag¶
- 直接指定测试
- Ex: - picking_ids[0].state == “done” - state == “manual”
comment¶
#<!– Resource: sale.order –>
Asserts and Python code¶
为了创建一个发票,python 代码应该这样写:
- -
- !python {model: account.invoice}: |
- self.action_move_create(cr, uid, [ref(“invoice1”)])
发票必须在 draft 状态:
- -
- !assert {model: account.invoice , id: invoice1, string: “the invoice is now in Draft state”}:
- - state == “draft”
测试所有在树形数据结构的账户, 我们写下面的 python 代码:
- -
- !python {model: account.account}:
- ids = self.search(cr, uid, [])
accounts_list = self.read(cr, uid, ids[‘parent_id’,’parent_left’,’parent_right’])
accounts = dict((x[‘id’], x) for x in accounts_list)
log(“Testing parent structure for %d accounts”, len(accounts_list))
- for a in accounts_list:
- if a[‘parent_id’]:
- assert a[‘parent_left’]>accounts[a[‘parent_id’][0]][‘parent_left’]
assert a[‘parent_right’]<accounts[a[‘parent_id’][0]][‘parent_right’]
assert a[‘parent_left’]<a[‘parent_right’]
for a2 in accounts_list:
- assert not ((a2[‘parent_right’]>a[‘parent_left’])and
- (a2[‘parent_left’]<a[‘parent_left’])and
(a2[‘parent_right’]<a[‘parent_right’]))
- if a2[‘parent_id’]==a[‘id’]:
- assert(a2[‘parent_left’]>a[‘parent_left’])and(a2[‘parent_right’]<a[‘parent_right’])
运行测试¶
- 以扩展名 ‘.yml’ 保存文件
- 添加 yaml 文件到 ‘demo_xml’ 下
- 以参数 ‘–log-level=test’ 运行服务器
CSV Data Serialization¶
Since version 4.2, OpenERP provides a Comma-Separated-Values (CSV), spreadsheet-compatible data serialization format.
The basic format of an OpenERP CSV file is as follows:
"id","name","model_id:id","group_id:id","perm_read","perm_write","perm_create","perm_unlink"
"access_product_uom_categ_manager","product.uom.categ manager","model_product_uom_categ","product.group_product_manager",1,1,1,1
"access_product_uom_manager","product.uom manager","model_product_uom","product.group_product_manager",1,1,1,1
"access_product_ul_manager","product.ul manager","model_product_ul","product.group_product_manager",1,1,1,1
"access_product_category_manager","product.category manager","model_product_category","product.group_product_manager",1,1,1,1
"access_product_template_manager","product.template manager","model_product_template","product.group_product_manager",1,1,1,1
"access_product_product_manager","product.product manager","model_product_product","product.group_product_manager",1,1,1,1
"access_product_packaging_manager","product.packaging manager","model_product_packaging","product.group_product_manager",1,1,1,1
"access_product_uom_categ_user","product.uom.categ.user","model_product_uom_categ","base.group_user",1,0,0,0
"access_product_uom_user","product.uom.user","model_product_uom","base.group_user",1,0,0,0
"access_product_ul_user","product.ul.user","model_product_ul","base.group_user",1,0,0,0
"access_product_category_user","product.category.user","model_product_category","base.group_user",1,0,0,0
"access_product_template_user","product.template.user","model_product_template","base.group_user",1,0,0,0
"access_product_product_user","product.product.user","model_product_product","base.group_user",1,0,0,0
"access_product_packaging_user","product.packaging.user","model_product_packaging","base.group_user",1,0,0,0
Importing from a CSV¶
Instead of using .XML file, you can import .CSV files. It is simpler but the migration system does not migrate the data imported from the .CSV files. It’s like the noupdate attribute in .XML files. It’s also more difficult to keep track of relations between resources and it is slower at the installation of the server.
Use this only for [demo] data that will never been upgraded from one version of OpenERP to another.
The name of the object is the name of the CSV file before the first ‘-‘. You must use one file per object to import. For example, to import a file with partners (including their multiple contacts and events), the file must be named like one of the following example:
- res.partner.csv
- res.partner-tiny_demo.csv
- res.partner-tiny.demo.csv
Structure of the CSV file¶
- Separator to use:
,- Quote character for strings:
"(optional if no separator is found in field values)- Encoding to use:
UTF-8- No whitespace allowed around separators if not using quote characters
- Be sure to configure your CSV export software (e.g. spreadsheet editor) with the above parameters
Exporting demo data and import it from a module¶
You can import .CSV file that have been exported from the OpenERP client. This is interesting to create your own demo module. But both formats are not exactly the same, mainly due to the conversion: Structured Data -> Flat Data -> Structured Data.
The name of the column (first line of the .CSV file) use the end user term in his own language when you export from the client. If you want to import from a module, you must convert the first column using the fields names. Example, from the partner form:
Name,Code,Contacts/Contact Name,Contacts/Street,Contacts/Zipbecomes:
name,ref,address/name,address/street,address/zipWhen you export from the OpenERP client, you can select any many2one fields and their child’s relation. When you import from a module, OpenERP tries to recreate the relations between the two resources. For example, do not export something like this from a sale order form - otherwise OpenERP will not be able to import your file:
Order Description,Partner/Name,Partner/Payable,Partner/Address/NameTo find the link for a many2one or many2many field, the server uses the name_search function when importing. So, for a many2one field, it is better to export the field ‘name’ or ‘code’ of the related resource only. Use the more unique one. Be sure that the field you export is searchable by the name_search function. (the ‘name’ column is always searchable):
Order Description,Partner/CodeChange the title of the column for all many2many or many2one fields. It’s because you export the related resource and you import a link on the resource. Example from a sale order: Partner/Code should become partner_id and not partner_id/code. If you kept the
/code, OpenERP will try to create those entries in the database instead of finding references to existing ones.Many2many fields. If all the exported data contains 0 or 1 relation on each many2many fields, there will be no problem. Otherwise, the export will result in one line per many2many. The import function expects to get all many2many relations in one column, separated by a comma.
So, you have to make the transformation. For example, if the categories “Customer” and “Supplier” already exists:
name,category_id Smith, "Customer, Supplier"If you want to create these two categories you can try
name,category_id/name Smith, "Customer, Supplier"But this does not work as expected: a category “Customer, Supplier” is created. The solution is to create an empty line with only the second category:
name,category_id/name Smith, Customer ,SupplierNote the comma before “Supplier”!
Read only fields. Do not try to import read only fields like the amount receivable or payable for a partner. Otherwise, OpenERP will not accept to import your file.
Exporting trees. You can export and import tree structures using the parent field. You just have to take care of the import order. The parent have to be created before his child’s.
Use record id like in xml file¶
It’s possible to define an id for each line of the csv file. This allow to define references between records:
id, name, parent_id:id record_one, Father, record_two, Child, record_one
If you do this, the line with the parent data must be before the child lines in the file.
Multiple CSV Files¶
Importing from multiple CSV a full group of linked data¶
It’s possible to import a lot of data, with multiple CSV files imported as a single operation. Assume we have a database with books and authors with a relation many2many between book and author.
And that you already have a file with a lot of books (like a library) and an other file with a lot of authors and a third file with the links between them.
How to import that easily in openERP ?
Definition of an import module¶
You can do this in the module you have defined to manage yours books and authors. but Sometimes, the tables to import can also be in several modules.
For this example, let’s say that ‘book’ object is defined in a module called ‘library_management’ and that ‘Author’ object in a module called ‘contact_name’.
In this case, you can create a ‘fake’ module, just to import the data for all these multiples modules. Call this importation module : ‘import_my_books’.
You create this module as others modules of OpenObject :
- create a folder ‘import_my_books’
- inside, create a ‘__init__.py’ file with only one line : import import_my_books
- again, in the same folder, create a ‘__openerp__.py’ file and in this file, write the following code :
# -*- encoding: utf-8 -*-
{
'name': 'My Book Import',
'category': 'Data Module 1',
'init_xml':[],
'author': 'mySelf & I',
'depends': ['base','library_management','contact_name'],
'version': '1.0',
'active': False,
'demo_xml': [],
'update_xml':['contact_name.author.csv','library.book.csv'],
'installable': True
}
Creation of CSV files¶
For the CSV files, you’ll import one after the other.
So you have to choose in which way you’ll treat the many2many relation. For our example, we’ve choose to import all the authors, then all the books with the links to the authors.
- authors CSV file
You have to put your data in a CSV file without any link to books (because the book ids will be known only AFTERWARDS...) For example : (“contact_name.author.csv”)
id,last_name,first_name,type
author_1,Bradley,Marion Zimmer,Book writer
author_2,"Szu T'su",,Chinese philosopher
author_3,Zelazny,Roger,Book writer
author_4,Arleston,Scotch,Screen Writer
author_5,Magnin,Florence,Comics Drawer
...
1. Books CSV file
Here, you can put the data about your books, but also, the links to the authors, using the same id as the column ‘id’ of the author CSV file. For example : (“library.book.csv” )
id,title,isbn,pages,date,author_ids:id
book_a,Les Cours du Chaos,1234567890123,268,1975-12-25,"author_3"
book_b,"L'art de la Guerre, en 219 volumes",1234567890124,1978-01-01,"author_2"
book_c,"new marvellous comics",1587459248579,2009-01-01,"author_5,author_4"
...
Five remarks :
- the field content must be enclosed in double quotes (”) if there is a double quote or a comma in the field.
- the dates are in the format YYYY-MM-DD
- if you have many ids in the same column, you must separate them with a comma, and, by the way, you must enclosed the content of the column between double quotes...
- the name of the field is the same as the name of the field in the class definition AND must be followed by ‘:id’ if the content is an ID that must be interpreted by the import module. In fact, “author_4” will be transformed by the import module in an integer id for the database module and this numerical id will be put also in the table between author and book, not the literal ID (author_4).
- the encoding to be used by the CSV file is the ‘UTF-8’ encoding
Data Migration - Import / Export¶
Data Importation¶
Introduction¶
There are different methods to import your data into OpenERP:
- Through the web-service interface
- Using CSV files through the client interface
- Building a module with .XML or .CSV files with the content
- Directly into the SQL database, using an ETL
Importing data through a module¶
The best way to import data in OpenERP is to build a module that integrates all the data you want to import. So, when you want to import all the data, you just have to install the module and OpenERP manages the different creation operations. When you have lots of different data to import, we sometimes create different modules.
So, let’s create a new module where we will store all our data. To do this, from the addons directory, create a new module called data_yourcompany.
- mkdir data_yourcompany
- cd data_yourcompany
- touch __init__.py
You must also create a file called __openerp__.py in this new module. Write the following content in this module file description.
{
'name': 'Module for Data Importation',
'version': '1.0',
'category': 'Generic Modules/Others',
'description': "Sample module for data importation.",
'author': 'Tiny',
'website': 'http://www.openerp.com',
'depends': ['base'],
'init_xml': [
'res.partner.csv',
'res.partner.address.csv'
],
'update_xml': [],
'installable': True,
'active': False,
}
The following module will import two different files:
- res.partner.csv : a CSV file containing records of the res.partner object
- res.partner.address.csv : a CSV file containing records of the res.partner.address object
Once this module is created, you must load data from your old application to .CSV file that will be loaded in OpenERP. OpenERP has a builtin system to manage identifications columns of the original software.
For this exercise, we will load data from another OpenERP database called old. As this database is in SQL, it’s quite easy to export the data using the command line postgresql client: psql. As to get a result that looks like a .CSV file, we will use the following arguments of psql:
- -A : display records without space for the row separators
- -F , : set the separator character as ‘,’
- –pset footer : don’t write the latest line that looks like “(21 rows)”
When you import a .CSV file in OpenERP, you can provide a ‘id’ column that contains a uniq identification number or string for the record. We will use this ‘id’ column to refer to the ID of the record in the original application. As to refer to this record from a many2one field, you can use ‘FIELD_NAME:id’. OpenERP will re-create the relationship between the record using this uniq ID.
So let’s start to export the partners from our database using psql: ::
psql trunk -c "select 'partner_'||id as id,name from res_partner"
-A -F , --pset footer > res.partner.csv
This creates a res.partner.csv file containing a structure that looks like this:
id,name
partner_2,ASUStek
partner_3,Agrolait
partner_4,Camptocamp
partner_5,Syleam
By doing this, we generated data from the res.partner object, by creating a uniq identification string for each record, which is related to the old application’s ID.
Now, we will export the table with addresses (or contacts) that are linked to partners through the relation field: partner_id. We will proceed in the same way to export the data and put them into our module:
psql trunk -c "select 'partner_address'||id as id,name,'partner_'||
partner_id as \"partner_id:id\" from res_partner_address"
-A -F , --pset footer > res.partner.address.csv
This should create a file called res.partner.address with the following data:
id,name,partner_id:id
partner_address2,Benoit Mortier,partner_2
partner_address3,Laurent Jacot,partner_3
partner_address4,Laith Jubair,partner_4
partner_address5,Fabien Pinckaers,partner_4
When you will install this module, OpenERP will automatically import the partners and then the address and recreate efficiently the link between the two records. When installing a module, OpenERP will test and apply the constraints for consistency of the data. So, when you install this module, it may crash, for example, because you may have different partners with the same name in the system. (due to the uniq constraint on the name of a partner). So, you have to clean your data before importing them.
If you plan to upload thousands of records through this technique, you should consider using the argument ‘-P’ when running the server.
openerp_server.py -P status.pickle --init=data_yourcompany
This method provides a faster importation of the data and, if it crashes in the middle of the import, it will continue at the same line after rerunning the server. This may preserves hours of testing when importing big files.
Using OpenERP’s ETL¶
The next version of OpenERP will include an ETL module to allow you to easily manages complex import jobs. If you are interested in this system, you can check the complete specifications and the available prototype at this location:
bzr branch lp:~openerp-commiter/openobject-addons/trunk-extra-addons/etl
... to be continued ...
Data Loading¶
During OpenERP installation, two steps are necessary to create and feed the database:
- Create the SQL tables
- Insert the different data into the tables
The creation (or modification in the case of an upgrade) of SQL tables is automated thanks to the description of objects in the server.
Into OpenERP, all the logic of the application is stored in the database. We find for example:
- the definitions of the reports,
- the object default values,
- the form description of the interface client,
- the relations between the menu and the client buttons, ...
There must be a mechanism to describe, modify and reload the different data. These data are represented into a set of XML files that can possibly be loaded during start of the program in order to fill in the tables.
Upgrading¶
Warning
This section needs to be rewritten or improved. If you think you can contribute to this effort, and are already familiar with Launchpad and OpenERP’s source control system, Bazaar, please have a look at:
Upgrading Server, Modules¶
The upgrade from version to version is automatic and doesn’t need any special scripting on the user’s part. In fact, the server is able to automatically rebuild the database and the data from a previously installed version.
The tables are rebuilt from the current module definitions. To rebuild the tables, the server uses the definition of the objects and adds / modifies database fields as necessary.
To invoke a database upgrade after installing a new version, you need to start the server with the –update=all argument :
openerp-server.py --update=all
You can also only upgrade specific modules, for example:
openerp-server.py --update=account,base
The database is rebuilt according to information provided in XML files and Python Classes. You can also execute the server with –init=all. The server will then rebuild the database according to the existing XML files on the system, delete all existing data and return OpenERP to its basic configuration.
Detailed update operations¶
OpenERP has a built-in migration and upgrade system which allows updates to be nearly (or often) automatic. This system also allows to easily include custom modules.
Table/Object structure¶
When you run openerp-server with option --init or --update, the table
structure is updated to match the new description that is in Python code. Fields
that are removed from Python code are not removed from the postgresql database
to avoid losing data.
So, simply running with --update or --init, will upgrade your table structure.
It’s important to run --init=module the first time you install the module.
Next time, you must use the --update=module argument instead of the init
one. This is because --init loads resources that are loaded only once and
never upgraded (i.e., resources with no id="" attribute or within a
<data noupdate="1"> tag). Resources with the noupdate attribute will still
be created if they do not exist at upgrade time. This can be overridden by marking
a record with forcecreate="False".
数据¶
Some data is automatically loaded at the installation of OpenERP:
- views, actions, menus,
- workflows,
- demo data
This data is also migrated to a new version if you run –update or –init.
工作流¶
Workflows are also upgraded automatically. If some activities are removed, the documents states evolves automatically to the preceding activities. That ensure that all documents are always in valid states.
You can freely remove activities in your XML files. If workitems are in this activity, they will evolve to the preceding unlinked activity. And after the activity will be removed.
开发过程中需要注意的事项¶
Since version 3.0.2 of OpenERP, you can not use twice the same ‘id=”...”’ during resource creation in your XML files, unless they are in two different modules.
Resources which don’t contain an id are created (and updated) only once; at the installation of the module or when you use the –init argument.
If a resource has an id and this resource is not present anymore in the next version of the XML file, OpenERP will automatically remove it from the database. If this resource is still present, OpenERP will update the modifications to this resource.
If you use a new id, the resource will be automatically created at the next update of this module.
Use explicit id declaration !, Example:
- view_invoice_form,
- view_move_line_tree,
- action_invoice_form_open, ...
It is important to put id=”....” to all record that are important for the next version migrations. For example, do not forget to put some id=”...” on all workflows transitions. This will allows OpenERP to know which transition has been removed and which transition is new or updated.
自定义模块¶
For example, if you want to override the view of an object named ‘invoice_form’ in your xml file (id=”invoice_form”). All you have to do is redefine this view in your custom module with the same id. You can prefix ids with the name of the module to reference an id defined in another module.
例子:
<record model=”ir.ui.view” id=”account.invoice_form”> ... <record>
This will override the invoice form view. You do not have to delete the old view, like in 3.0 versions of OpenERP.
Note that it is often better to use view inheritance instead of overwriting views.
In this migration system, you do not have to delete any resource. The migration system will detect if it is an update or a delete using id=”...” attributes. This is important to preserve references during migrations.
演示数据¶
Demo data does not have to be upgraded; because it was probably modified or
deleted by users. To avoid demo data being upgraded you can put a
noupdate="1" attribute in the <data> tag of your .xml data files.
Summary of update and init process¶
init:
修改/添加/删除演示数据和内置数据
更新:
modify/add/delete non demo data
内置(非演示)数据例子:
- 菜单结构,
- 视图定义,
- 工作流描述, ...
- Everything that has an id attribute in the XML data declaration (if no attr noupdate=”1” in the header)
What’s going on during the update process:
- If you manually added data within the client:
- the update process will not change them
- If you dropped data:
- if it was demo data, the update process will do nothing
- if it was built-in data (like a view), the update process will recreate it
- If you modified data (either in the .XML or the client):
- if it’s demo data: nothing
- if it’s built-in data, data are updated
- If built-in data have been deleted in the .XML file:
- this data will be deleted in the database.